🔍 Self-Ask:LLM Agent架构的决策链路模式 | 智能体推理框架与工具调用实践
作为程序员,我们习惯将复杂问题分解为可管理的子任务,这正是递归和分治算法的核心思想。那么,如何让AI模型也具备这种结构化思考能力?本文深入剖析Self-Ask推理模式的工作原理、实现方法与最佳实践,帮助你构建具有清晰推理链路的AI系统,就像调试一个递归函数一样追踪AI的"思考过程"。
🔍 Self-Ask:AI 推理的"侦探模式"
什么是 Self-Ask 模式?
Self-Ask(自问自答) 是一种AI推理策略,通过问题分解和逐步解答来处理复杂问题。2022年由斯坦福大学研究者提出,旨在提升大语言模型的多步骤推理能力。核心机制是将一个复杂问题拆分为多个简单子问题,逐一解答后整合结果。值得注意的是,Self-Ask不只是agent的设计模式,更是一种提示词工程模式,以及大模型微调的一种设计模式,体现了AI系统设计的多层次应用价值。
Self-Ask与其他推理方法比较
| 推理方法 | 核心特点 | 与Self-Ask区别 |
|---|---|---|
| Chain-of-Thought | 连续思考流 | Self-Ask更结构化 |
| ReAct | 环境交互 | Self-Ask专注内部推理 |
| Reflexion | 自我反思 | Self-Ask侧重问题分解 |
Self-Ask可与外部工具自然结合,当需要最新信息时可调用搜索工具获取答案。
Self-Ask的优缺点
从工程实现角度看,Self-Ask类似于软件架构中的分层设计模式,其核心优势在于将复杂推理转化为可追踪的线性执行路径,实现了类似日志系统的调试便利性和模块化架构的可维护性。这种结构化思考方式遵循单一职责原则,使每个子问题独立求解,有效降低了系统复杂度(从潜在的指数级降至O(n)线性复杂度)。然而,这种递归式推理也带来了类似函数调用栈的性能开销,增加了token消耗;同时,整体效果高度依赖于初始问题分解的质量,这与系统设计中接口定义的重要性类似。在简单任务上,Self-Ask可能违反YAGNI原则,引入不必要的复杂性;而在复杂推理链上,则可能面临类似大型应用中的状态管理挑战,导致上下文信息丢失。
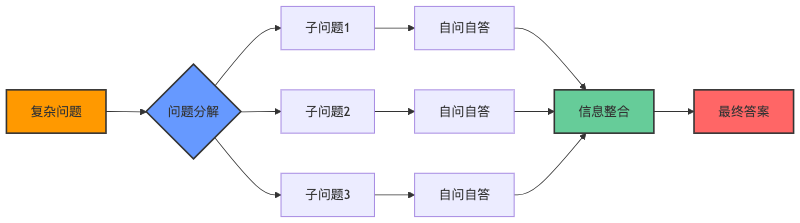
Self-Ask模式的工作流程:将复杂问题分解为一系列子问题
🧩 Self-Ask 的工作原理
Self-Ask通过三步法解决复杂问题:
1️⃣ 问题分解
复杂问题→简单子问题
2️⃣ 自问自答循环
问题:谁是第一个登上月球的宇航员的妻子?
自问:谁是第一个登上月球的宇航员?
自答:尼尔·阿姆斯特朗。自问:尼尔·阿姆斯特朗的妻子是谁?
自答:珍妮特·希顿(Janet Shearon)。最终答案:珍妮特·希顿。
3️⃣ 信息整合
子问题答案→最终解答
⚙️ Self-Ask 实现方法
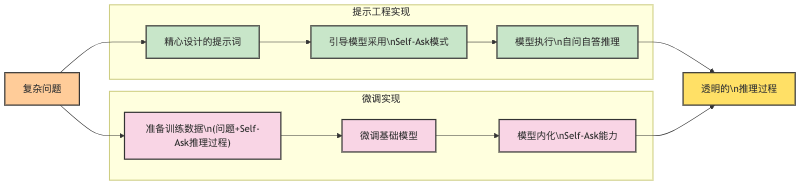
Self-Ask有三种实现路径:提示工程、Agent和模型微调。
📝 提示工程实现
| |
提升效果技巧:通过添加示例引导、使用领域特定提示和整合外部工具调用,可显著提升Self-Ask的表现质量。
如下是论文Measuring and Narrowing the Compositionality Gap in Language Models中的例子:

🤖 Agent实现
Self-Ask在Agent系统中的应用尤为强大,特别是与搜索工具结合时。 langchain 框架中也集成了开箱即用的 self-ask-search agent 工具。

Self-Ask Agent工作流程:问题处理、自问自答循环与结果整合三阶段
实际应用示例:
问题:2024年奥运会在哪个城市举办,这个城市有什么著名景点?
自问:2024年奥运会在哪个城市举办?
搜索:2024年奥运会举办城市
搜索结果:2024年夏季奥运会在法国巴黎举办。 自答:2024年奥运会在法国巴黎举办。自问:巴黎有哪些著名景点?
搜索:巴黎著名景点
搜索结果:巴黎著名景点包括埃菲尔铁塔、卢浮宫、凯旋门、巴黎圣母院、蒙马特高地、塞纳河、香榭丽舍大街等。 自答:巴黎有许多世界闻名的景点,包括埃菲尔铁塔、卢浮宫、凯旋门、巴黎圣母院、蒙马特高地和塞纳河等。最终答案:2024年奥运会将在法国巴黎举办。巴黎的著名景点包括埃菲尔铁塔、卢浮宫、凯旋门、巴黎圣母院、蒙马特高地、塞纳河和香榭丽舍大街等世界闻名的旅游胜地。
这个例子展示了Self-Ask如何与搜索工具结合,处理需要实时信息的复杂问题。Agent通过自问自答的方式,将问题分解为两个子问题,并利用搜索工具获取最新信息,最终整合成完整答案。这种方法特别适合处理需要多步骤推理且涉及外部知识的问题。
🔄 模型微调实现
流程:准备数据 → 微调模型 → 评估优化
优势:微调模型在表现一致性、领域特定优化和token消耗减少方面具有明显优势。
挑战:实施过程中面临大量训练数据需求、高昂计算成本和模型需定期更新等技术挑战。
简单微调实现例子:
| |
这个例子展示了如何使用Transformers库微调一个基础语言模型来执行Self-Ask推理。通过准备包含问题和自问自答格式回答的训练数据,模型学会了这种推理模式,可以自动将复杂问题分解并逐步解答。微调后的模型无需每次都提供详细的提示,就能生成结构化的自问自答推理过程。
📚 总结与实践建议

从工程角度看,Self-Ask本质上是一种递归问题解决模式,类似于我们编写的分治算法。它通过"问题分解→子问题求解→结果合并"这个经典流程提升AI推理能力。实践中,建议从简单场景入手调试,关注整个推理链路而非仅关注输出结果,就像我们debug代码时需要跟踪完整执行路径一样。在实际项目中,可以灵活组合工具调用API、CoT等技术,构建更强大的推理系统。正如福尔摩斯的名言:“排除不可能后,剩下的即是真相”—Self-Ask正是这种逐步缩小解空间的编程思维在AI领域的应用。