提示工程实战指南:从Zero-Shot到Graph Prompting,7大核心技术全解析
不同场景下的提示词优化模式
引言
随着大型语言模型(LLM)的发展,提示工程(Prompt Engineering)已成为有效使用这些模型的关键技能。不同的提示技术适用于不同的场景,本文将介绍七种主要的提示优化模式,并分析它们的适用场景和优缺点。
1. Zero-Shot Prompting(零样本提示)
零样本提示就像你对朋友直接说"帮我查下天气"一样简单自然,不需要给任何例子就能搞定。只要清楚表达需求,AI就能凭借它已有的知识立刻行动起来,这种方式不仅简单高效,还能节省token空间,特别适合那些常见的文本分类、简单问答和内容摘要任务。
不过零样本提示也有缺点,比如有时候会产生一些幻觉,处理复杂推理或专业领域的任务时表现有限。想要用好它,需要使用明确的动词指令(比如"分类"、“总结”、“翻译”),指定清晰的输出格式(像JSON或Markdown),还需要加上一些约束条件(比如字数限制)来获得最佳效果。指令越清晰,效果越好,模糊不清的提示会让AI摸不着头脑,给出不太理想的回答。
示例:
Zero-shot提示的核心在于利用模型预训练知识直接完成任务,无需提供示例。下面是一个复杂的zero-shot示例,涉及多步骤分析和结构化输出:
| |
这个示例通过明确的多步骤指令、复杂的分析要求和结构化输出格式三个关键要素,测试模型的综合分析能力和遵循复杂指令的能力,同时保持zero-shot特性(无需提供完成示例)。相比简单的情感分析,这个任务需要模型理解科学文献、提取多层次信息、进行批判性思考并生成创造性建议,考验了模型在专业领域的zero-shot能力极限。
2. Few-Shot Prompting(少样本提示)
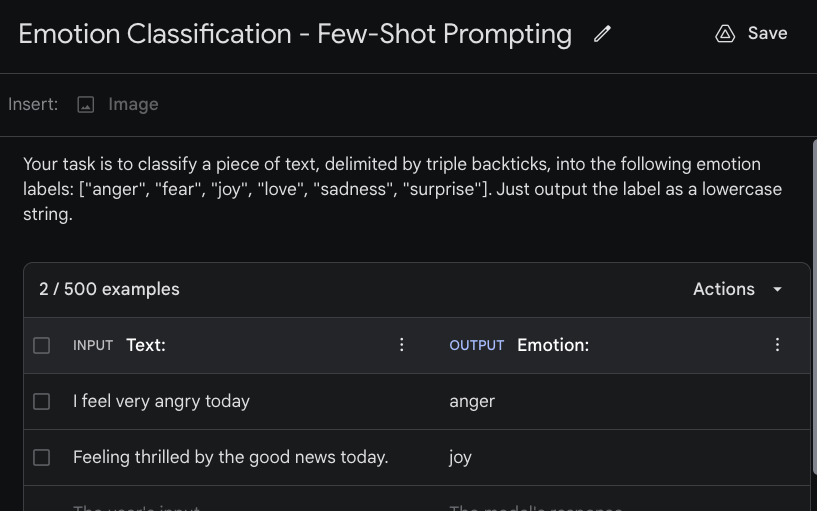
图:Few-Shot Prompting示例 (来源: Prompt Engineering Guide)
少样本提示通过提供几个"范例"让AI理解任务,就像教朋友新游戏时直接玩几轮给他看。它利用模型的上下文学习能力,只需3-5个精心设计的例子,就能让模型举一反三处理新问题。这种方法不需要重新训练模型,却能清晰传达期望,提升陌生领域表现,并确保输出格式一致。特别适合需要特定输出格式、专业领域或自定义分类系统的任务。不过它对示例质量高度敏感,容易出现"标签偏见",且示例数量有限。使用时,示例应覆盖主要变体,保持格式一致,确保区分度,对于复杂任务可结合CoT使用。
示例:
| |
3. Chain-of-Thought (CoT) Prompting(思维链提示)
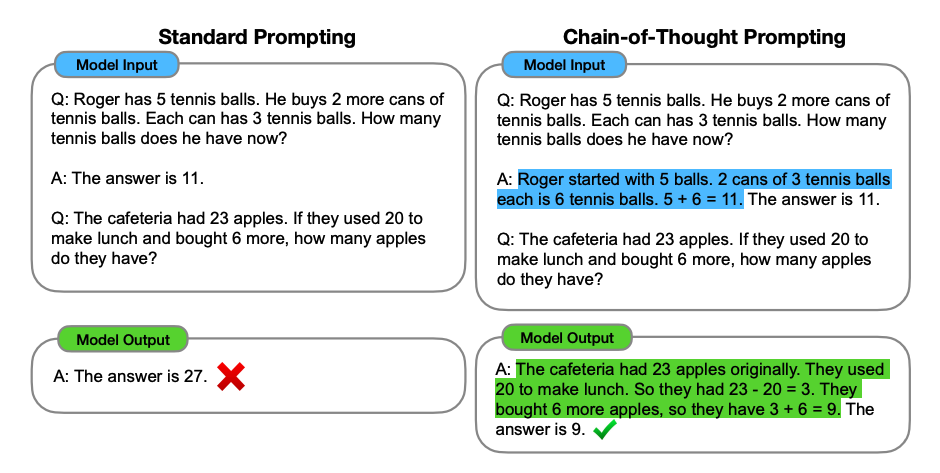 图:Chain-of-Thought Prompting框架 (来源: Wei et al. 2022)
图:Chain-of-Thought Prompting框架 (来源: Wei et al. 2022)
思维链提示引导模型展示完整的推理过程,通过将复杂问题分解为连续的中间步骤,利用语言模型的推理能力而非单纯记忆,并通过显式推理减少错误累积,显著提高模型在推理任务上的表现。
Chain-of-Thought Prompting 特别适合数学问题、多步逻辑推理和需要解释答案来源的任务。它通过展示逐步推理过程,显著提高了模型在复杂推理任务上的表现,是符号推理和规划问题的理想选择。值得注意的是,CoT对模型规模表现出明显的敏感性,是大型语言模型的"涌现能力"之一。然而,CoT可能产生看似合理但实际错误的推理链,对于特别复杂的问题可能需要更结构化的引导,且其效果受到底层模型推理能力的限制。
示例:
| |
思维链方法发展出多个重要变体:零样本CoTKojima et al., 2022通过简单触发短语激发推理;自洽性CoTWang et al., 2022采用多路径推理和多数表决提高可靠性;自动CoTZhang et al., 2022可自动生成高质量示例。有兴趣的同学可以扩展阅读。
4. Tree of Thoughts (ToT)(思维树)
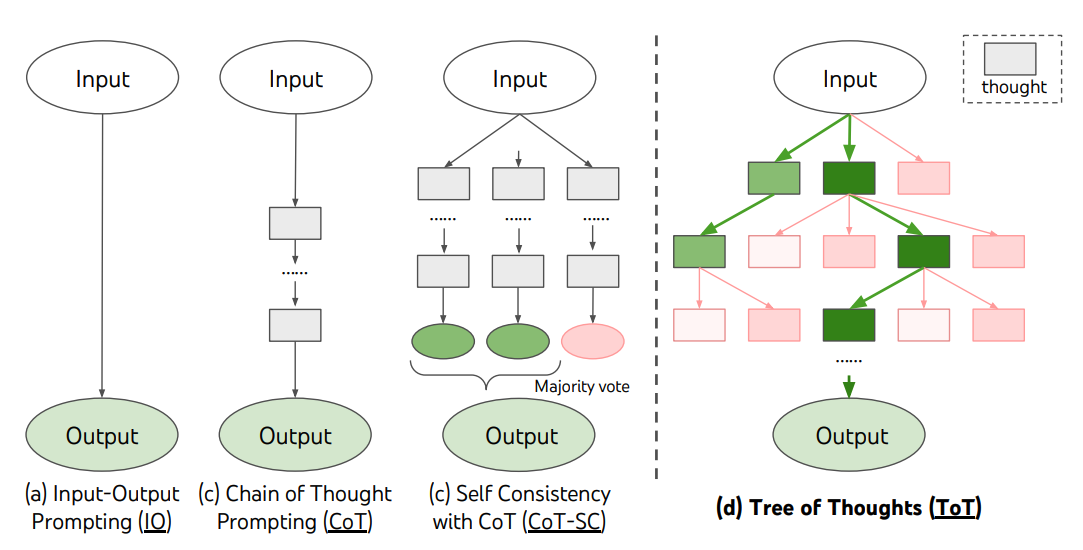 图:Tree of Thoughts框架 (来源: Yao et al. 2023)
图:Tree of Thoughts框架 (来源: Yao et al. 2023)
思维树框架将CoT扩展为树状结构,通过将思考过程构建为树状结构,在每个决策点生成多个思考分支,结合搜索算法探索解决方案空间,并利用自评估机制选择最优路径,来解决需要探索或战略前瞻的复杂问题。
ToT 特别适合需要探索多种解决方案的复杂任务,如战略游戏(国际象棋、24点等)和需要前瞻性思考的场景。它通过维护多个并行推理路径,支持回溯和前瞻性规划,结合搜索算法(如BFS、DFS、Beam Search)来探索解决方案空间。ToT的自我评估机制使其能够在复杂决策和规划问题中表现出色。然而,ToT的计算成本和实现复杂度都较高,需要有效的评估机制来指导搜索过程,且在某些情况下可能陷入局部最优解而无法找到全局最优解。
算法流程:
- 思考:在每个节点生成多个可能的思考
- 评估:评估每个思考的价值
- 搜索:选择最有希望的路径继续探索
- 迭代:重复上述过程直到解决问题
5. ReAct Prompting(推理+行动)
flowchart LR
S([开始]) --> T[思考]
T --> A[行动]
A --> O[观察]
O -->|循环| T
O -->|目标达成| R([回答])
style S fill:#f8f8f8,stroke:#333
style T fill:#e6f7ff,stroke:#333,stroke-width:2px
style A fill:#fff7e6,stroke:#333,stroke-width:2px
style O fill:#e6ffe6,stroke:#333,stroke-width:2px
style R fill:#f8f8f8,stroke:#333flowchart LR
S([开始]) --> T[思考]
T --> A[行动]
A --> O[观察]
O -->|循环| T
O -->|目标达成| R([回答])
style S fill:#f8f8f8,stroke:#333
style T fill:#e6f7ff,stroke:#333,stroke-width:2px
style A fill:#fff7e6,stroke:#333,stroke-width:2px
style O fill:#e6ffe6,stroke:#333,stroke-width:2px
style R fill:#f8f8f8,stroke:#333图:ReAct的"思考-行动-观察"循环迭代过程
ReAct(Reasoning+Acting)结合推理轨迹和实际行动,通过交替进行推理(Reasoning)和行动(Acting),利用外部工具获取实时信息,基于观察结果调整推理路径,形成**“思考-行动-观察"闭环**,允许模型与外部工具和环境交互获取信息,形成闭环决策系统。
ReAct Prompting 特别适合需要外部知识的问答系统和多步骤决策制定,通过交替进行推理和行动,显著减少事实幻觉并支持复杂任务分解。它主要应用于四类场景:信息检索与验证(如查询实时数据、验证事实)、复杂问题求解(如数学计算、编程调试)、动态决策制定(如投资决策、旅行规划)和交互式任务处理(如智能客服、数据采集)。虽然ReAct强大灵活,但也高度依赖外部工具质量,且在某些情况下行动序列可能变得冗长低效。
示例:
| |
工具集成与应用场景: ReAct可以集成多种外部工具以增强其能力,包括搜索引擎获取实时信息、计算器处理数学运算、专业知识库查询系统、各类API服务以及代码执行环境等。这些工具使ReAct能够处理从日常信息查询到专业领域问题的广泛任务,特别适合需要最新信息或专业知识的场景,如旅游规划、技术支持、医疗咨询和金融分析等。
6. Reflexion(反思)
flowchart LR
A[行动
Actor] --> B[评估
Evaluator]
B -->|成功| D[任务完成]
B -->|失败| C[反思
Reflector]
C -->|更新策略| A
style A fill:#ffcccc,stroke:#333,stroke-width:2px
style B fill:#ccffcc,stroke:#333,stroke-width:2px
style C fill:#ccccff,stroke:#333,stroke-width:2px
style D fill:#ffffcc,stroke:#333,stroke-width:2pxflowchart LR
A[行动Actor] --> B[评估
Evaluator] B -->|成功| D[任务完成] B -->|失败| C[反思
Reflector] C -->|更新策略| A style A fill:#ffcccc,stroke:#333,stroke-width:2px style B fill:#ccffcc,stroke:#333,stroke-width:2px style C fill:#ccccff,stroke:#333,stroke-width:2px style D fill:#ffffcc,stroke:#333,stroke-width:2px
图:Reflexion框架的三阶段循环过程 (基于 Shinn et al. 2023)
Reflexion框架通过语言反馈强化模型,使用三阶段循环:行动、评估、反思,提供语言化反馈而非数值奖励,记忆过去错误并形成改进策略,培养自我批评和元认知能力,使模型从错误中学习,实现自我改进的闭环系统。
系统组件:Reflexion框架由三个核心组件构成:行动者(Actor)负责执行任务,评估者(Evaluator)判断结果质量,反思器(Reflector)分析失败原因并提出改进策略,三者协同形成自我改进闭环。
场景与局限性:
Reflexion 特别适合需要从错误中学习的迭代任务,如编程问题调试和优化。它通过包含行动者、评估者和自我反思三个角色,形成完整的"行动-评估-反思"循环,能够从试错中学习并持续改进。Reflexion提供详细的语言反馈而非简单奖励,并维护反思记忆(Reflection Memory),使其在长期学习和自我改进场景中表现出色。然而,Reflexion需要高质量的评估机制,可能陷入局部最优解,且反思过程本身可能引入新的错误。此外,其计算和存储开销较大,对系统资源要求较高。
示例:
| |
7. Graph Prompting(图提示)
 图:Graph Prompting框架示例 (来源: Liu et al. 2023)
图:Graph Prompting框架示例 (来源: Liu et al. 2023)
Graph Prompting将提示结构化为有向图,通过将提示组织为节点和边的图结构,其中每个节点代表特定子任务或推理步骤,边表示任务之间的依赖关系和信息流,并支持条件分支和循环结构,允许模型按照预定义的路径进行推理和决策,实现更复杂的任务流程控制。
场景与局限性:
Graph Prompting 特别适合具有明确流程和依赖关系的复杂任务,如多步骤规划、条件决策和递归问题解决。它通过将大型任务分解为相互连接的子任务,有效降低了复杂性并提高了可控性,支持非线性推理路径和条件执行,使其在处理需要明确流程控制的任务时表现出色。Graph Prompting还支持模块化设计,便于重用和维护。然而,设计有效的图结构需要专业知识,实现复杂度较高,且在执行过程中可能出现错误累积。此外,大型图结构可能超出上下文窗口限制,需要特殊的处理机制。
示例:
flowchart LR
A["客户分析
输入: 客户年龄、收入、风险偏好
处理: 计算风险承受能力
输出: 风险评分(1-10)"] -->|风险评分≤3| B["保守型投资
处理: 筛选低风险产品
输出: 国债、货币基金等"]
A -->|风险评分4-7| C["平衡型投资
处理: 筛选中等风险产品
输出: 混合基金、蓝筹股等"]
A -->|风险评分>7| D["进取型投资
处理: 筛选高风险产品
输出: 成长股、行业基金等"]
B --> E["投资组合生成
输入: 推荐产品列表
处理: 生成多元化组合
输出: 投资建议"]
C --> E
D --> E
E --> F[最终投资建议报告]
style A fill:#f9d5e5,stroke:#333,stroke-width:2px
style B fill:#eeeeee,stroke:#333,stroke-width:2px
style C fill:#dddddd,stroke:#333,stroke-width:2px
style D fill:#cccccc,stroke:#333,stroke-width:2px
style E fill:#b5ead7,stroke:#333,stroke-width:2px
style F fill:#c7ceea,stroke:#333,stroke-width:2pxflowchart LR
A["客户分析输入: 客户年龄、收入、风险偏好
处理: 计算风险承受能力
输出: 风险评分(1-10)"] -->|风险评分≤3| B["保守型投资
处理: 筛选低风险产品
输出: 国债、货币基金等"] A -->|风险评分4-7| C["平衡型投资
处理: 筛选中等风险产品
输出: 混合基金、蓝筹股等"] A -->|风险评分>7| D["进取型投资
处理: 筛选高风险产品
输出: 成长股、行业基金等"] B --> E["投资组合生成
输入: 推荐产品列表
处理: 生成多元化组合
输出: 投资建议"] C --> E D --> E E --> F[最终投资建议报告] style A fill:#f9d5e5,stroke:#333,stroke-width:2px style B fill:#eeeeee,stroke:#333,stroke-width:2px style C fill:#dddddd,stroke:#333,stroke-width:2px style D fill:#cccccc,stroke:#333,stroke-width:2px style E fill:#b5ead7,stroke:#333,stroke-width:2px style F fill:#c7ceea,stroke:#333,stroke-width:2px
实现方式: Graph Prompting可通过多种方式实现:静态图预定义完整任务流程;动态图根据中间结果实时调整结构;嵌套图允许节点包含子图;也可与其他提示技术(如CoT、ReAct)结合形成混合方法,以适应不同复杂度的任务需求。
总结与最佳实践
提示工程是一门快速发展的学科,不同的提示技术适用于不同的场景。选择合适的提示技术应考虑任务复杂度、外部知识需求、解释性要求和可用计算资源。对于简单任务,Zero-Shot是首选;复杂推理问题适合使用CoT或ToT;需要外部知识时,ReAct表现出色;长期学习场景则应考虑Reflexion;而结构化流程任务则适合Graph Prompting。这些技术可以组合使用以应对更复杂的场景,如ReAct+Reflexion用于持续学习的交互式任务,Few-Shot+CoT提高复杂任务的示例有效性。随着模型能力的提升,建议持续关注提示工程的最新研究进展,并通过实践建立适合自己的提示库。
| 技术 | 优点 | 局限性 | 最佳适用场景 |
|---|---|---|---|
| Zero-Shot | 简单直接 | 依赖预训练知识 | 简单分类/生成 |
| Few-Shot | 明确任务要求 | 示例质量敏感 | 需要特定格式 |
| CoT | 展示推理过程 | 可能产生幻觉 | 复杂推理 |
| ToT | 多路径探索 | 计算成本高 | 战略决策 |
| ReAct | 结合外部知识 | 依赖工具质量 | 信息检索 |
| Reflexion | 从错误中学习 | 需要评估机制 | 长期学习 |
| Graph Prompting | 流程可控 | 设计复杂度高 | 结构化流程任务 |